1. 简介/动机
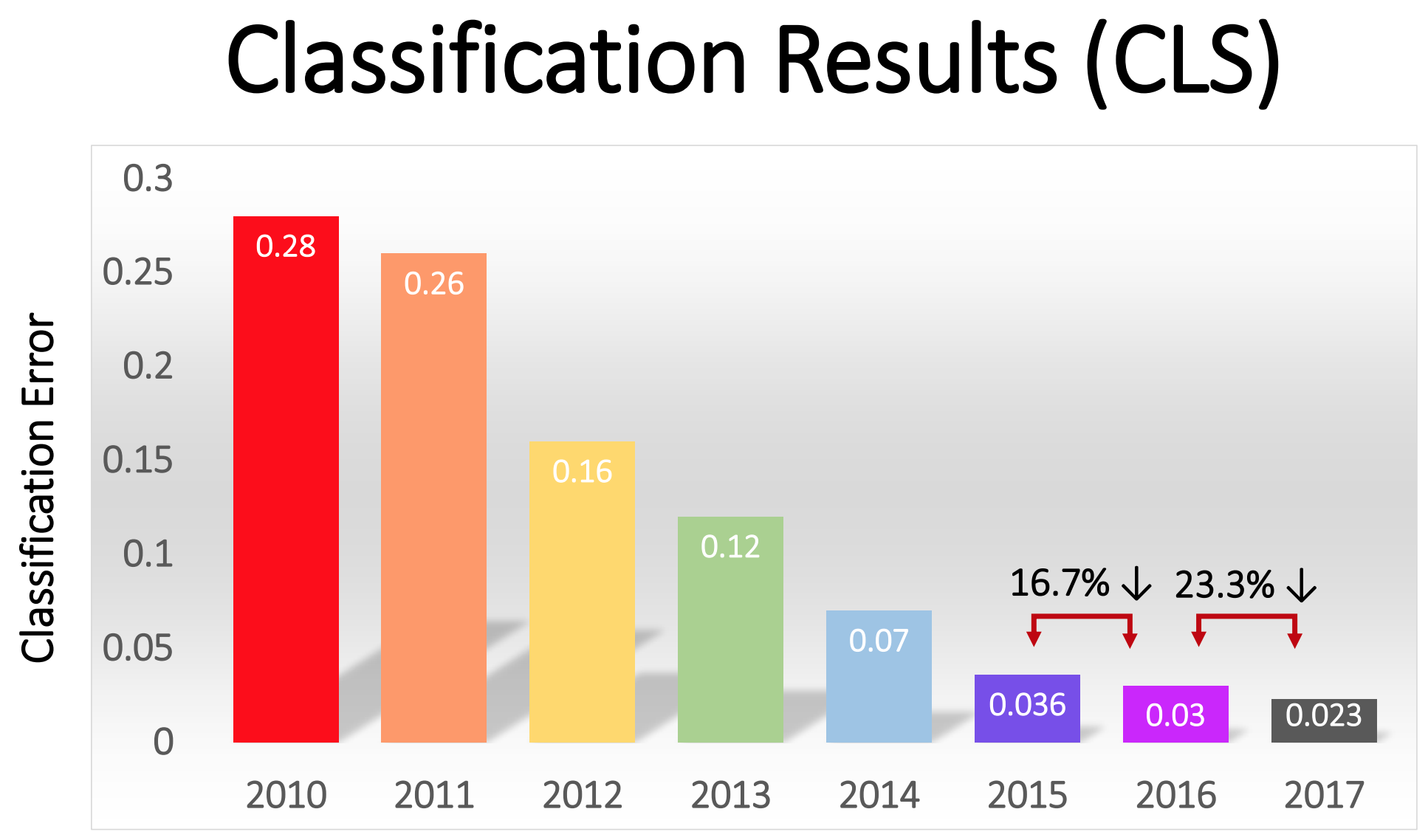
Squeeze-and-Excitation Networks(SENet)由自动驾驶公司Momenta和University of Oxford于2017年共同提出。作者认为尽管卷积操作能够有效地提取图像的特征信息,但这些特征的空间信息与通道维信息是杂糅在一起的,这会在一定程度上限制网络的表达能力,因此本文提出了一种被称为“特征重校准”(feature recalibration)的机制,通过对网络特征图各通道的相互依存关系进行重新建模,确保网络增加对含有有效信息的特征的敏感性,并抑制无用的特征,以达到改善网络的整体表达能力的目的。SENet以对测试集2.251%的top-5 error(相对于2016年冠军提升约25%)赢得了ILSVRC 2017图像分类挑战赛的冠军。截至目前,Squeeze-and-Excitation Networks这篇文章已被引约800次。
用一句话概括SENet: 通过学习的方式自动获取每个通道的重要程度,并依据这个重要程度去提升有用的特征并抑制对当前任务作用不大的特征,从而提升网络的表达能力(性能)。
2. Squeeze-and-Excitation(SE) Block
本文并未提出完整的网络结构,其工作主要是对现有卷积神经网络(VGG,ResNet,Inception)的改进。SE block是本文的核心,相较于标准的卷积层,SE block在其基础上又增加了Squeeze(挤压)、Excitation(激发)与Scale(比例整定)三种操作。
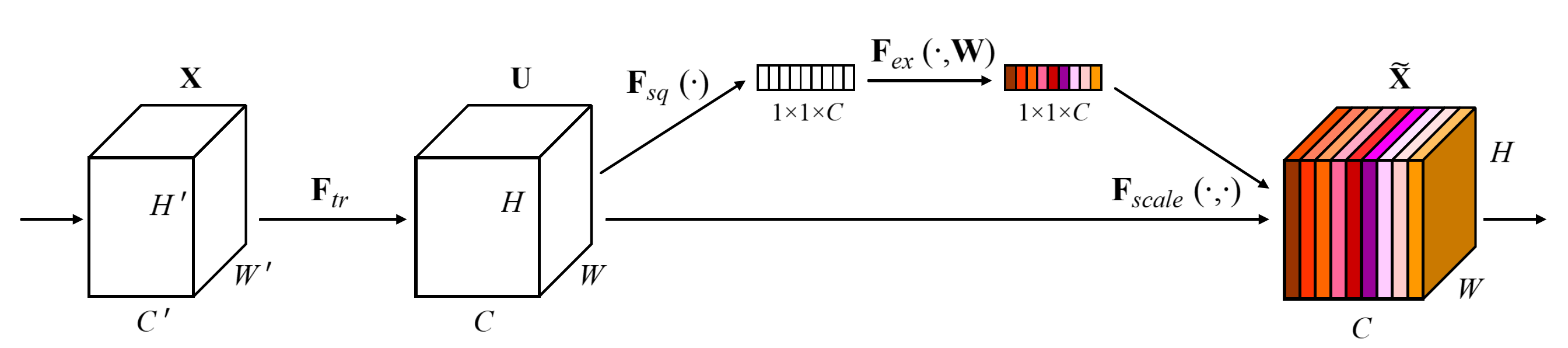 SE block如上图所示,其大致流程如下:
SE block如上图所示,其大致流程如下:
- 标准的卷积操作$\boldsymbol{F}_{tr}:\boldsymbol{X}\rightarrow \boldsymbol{U}, \boldsymbol{X}\in \mathbb{R}^{H’\times W’\times C’}, \boldsymbol{U}\in\mathbb{R}^{H\times W\times C}$,输入特征图为$\boldsymbol{X}$,输出特征图为$\boldsymbol{U}$;
- 使用Squeeze操作$\boldsymbol{F_{sq}}$处理$\boldsymbol{U}$,该操作通过Global Average Pooling将$\boldsymbol{U}$的空间维度$H\times W$上的信息压缩为单个数值,输出为$1\times 1\times C$的通道描述子;
- 使用Excitation操作$\boldsymbol{ {F}_{ex}}$处理$1\times 1\times C$的通道描述子,该操作通过两级全连接层对描述子进行非线性处理,最后使用Sigmoid函数将描述子的数值限定在$[0,1]$范围内,输出为$1\times 1\times C$的权重。
- Scale操作$\boldsymbol{ {F}_{scale}}$将权重与$\boldsymbol{U}$的对应通道相乘,通过对不同的通道赋予不同的权重来达到增强有用信息,抑制无效信息的作用。
2.1. 卷积操作 $F_{tr}$
- $\boldsymbol{F}_{tr}(·, \boldsymbol{\theta})$代表标准卷积操作,$\theta$表示卷积核的参数
- $\boldsymbol{X}$代表该卷积层输入的特征图,其尺寸为$H’\times W’\times C’$
- $\boldsymbol{U}$代表该卷积层输出的特征图,其尺寸为$H\times W\times C$
令$\boldsymbol{V}=[\boldsymbol{v_1}, \boldsymbol{v_2},\dots, \boldsymbol{v_C}]$ 代表该卷积层的卷积核,则经$\boldsymbol{F}_{tr}$的输出可记为$\boldsymbol{U}=[\boldsymbol{u_1}, \boldsymbol{u_2}, \dots, \boldsymbol{u_C}]$,其中 $\boldsymbol{v_c}=[\boldsymbol{v^1_c}, \boldsymbol{v^2_c},\dots \boldsymbol{v^{C’}_c}]$,$\boldsymbol{X}=[\boldsymbol{x}^1,\boldsymbol{x}^2,\dots \boldsymbol{x}^{C’}]$。
2.2. Squeeze $F_{sq}$
由公式可以看出,Squeeze操作的实质是对特征图$U\in\mathbb{R}^{H\times W\times C}$进行全局平均池化(global average pooling),即对尺寸为$H\times W\times C$的特征图在空间维度上进行特征压缩,将每个二维的特征通道变成一个实数,输出为$1\times 1\times C$,作者认为这些实数是对特征通道信息的总结,某种程度上具有全局的感受野,它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野。Squeeze操作使得SE block能够专注于特征图通道之间的相互关系。另外作者要利用的是通道间的相关性,而不是空间分布中的相关性,用GAP屏蔽掉空间上的分布信息能让后续Scale操作的计算更加准确。
2.3. Excitation $F_{ex}$

典型的 Excitation操作由两个全连接层构成,这意味着其中的参数可以在网络训练阶段的前、反向传播过程中得到学习和更新,这也正是SE block能够针对不同的输入模式动态地给出合理且有效的特征图权重的重要原因之一。Excitation用于建模通道之间的相关性,输出与输入特征相同数目的权重,使用一个以上全连接层的好处有两点:
- 增加SE block模块的非线性,从而更好地拟合通道间复杂的相关性。
- 可以在两层及以上的全连接层之间设置bottleneck结构,减少了参数量和计算量。
Excitation可以表示为:
- FC1的输入与输出特征的尺寸分别为$C$和$\frac{C}{r}$,其参数表示为$W_1\in\mathbb{R}^{\frac{C}{r}\times C}$,激活函数$\delta$为ReLU;
- FC2的输入与输出特征的尺寸分别为$\frac{C}{r}$和$C$,其参数表示为$W_2\in\mathbb{R}^{C\times \frac{C}{r}}$,激活函数$\sigma$为Sigmoid,FC2的输出为各特征图切片的权重,使用Sigmoid激活的目的是将权重限定在$[0,1]$范围内;
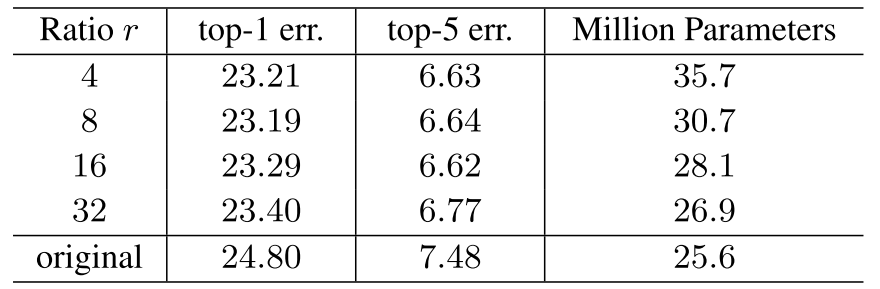
- $r$为缩减比(reduction ratio)。SENet需要在复杂度与性能之间进行权衡,因此在FC1与FC2之间设计bottleneck结构以减少SE block中可学习参数的数量。这种降维操作也有利于降低SE block对特定输入模式产生过拟合的风险。作者在实验中发现当$r=16$(将输入维度缩减为原来的$\frac{1}{16}$)时SE block使网络性能带来的提升最为明显。
Excitation为原有网络引入的额外参数量可以由以下公式计算:
- $r$为缩减比;
- $S$为原有网络所含有的stage数量,如VGG16有5个stage;
- $N_s$为stage $s$中所含有的block数量;
- $C_s$为stage $s$中各block中输出的特征通道数量。
2.4. Scale $F_{scale}$
Excitation输出的权重$\boldsymbol{s}\in\mathbb{R}^{1\times 1\times C}$看作是进行过特征选择后的每个特征通道的重要性,Scale操作通过乘法将其逐通道加权到先前的特征$U$上,完成在通道维度上的对原始特征的重新校准。
其中$\widetilde{X}=[ \boldsymbol { \widetilde {x}_1}, \boldsymbol {\widetilde {x}_2} ,\dots,\boldsymbol{\widetilde {x}_C}]$
$\boldsymbol{F}_{ scale}(\boldsymbol{u_c},s_c)$ 代表特征通道 $\boldsymbol{u}_c\in\mathbb{R}^{H\times W}$ 与标量 $s_c$ 的乘法。
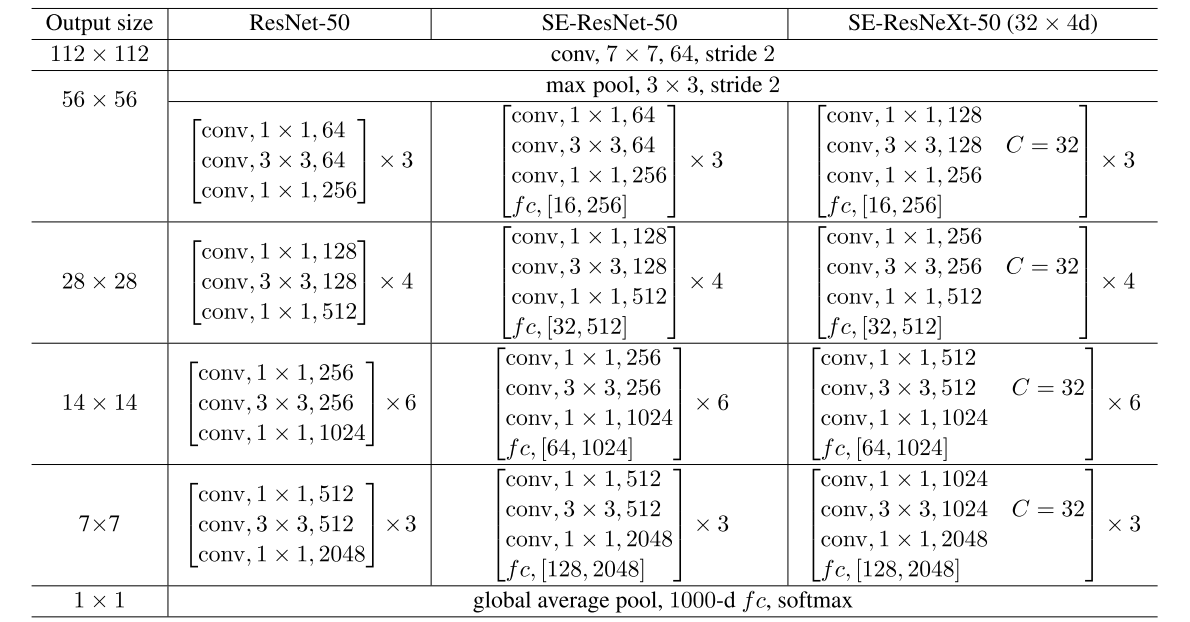
3. 在实际网络中的应用
SE block不仅能很容易地嵌入到诸如AlexNet、VGG之类的平坦网络当中,其灵活性也使得SE block能够嵌入到几乎任何使用了标准卷积层的网络当中,作者分别构造了Inception和ResNet这两个当时主流网络的SE版本。
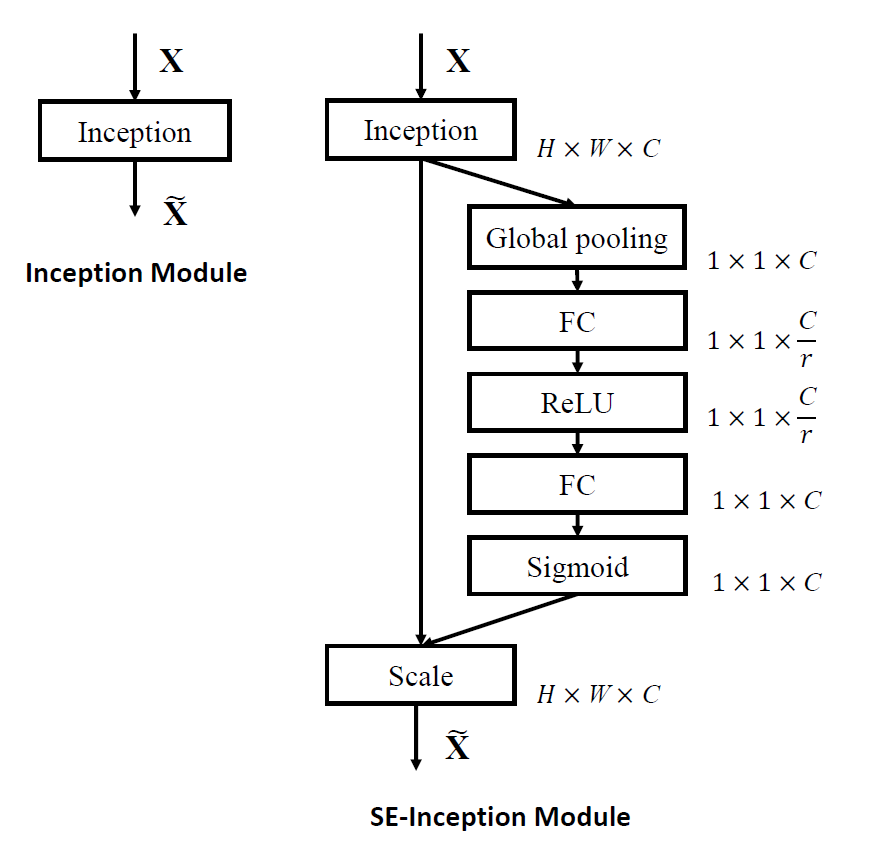
在SE-Inception中,Inception模块作为SE block的$\boldsymbol{F_{tr}}$。
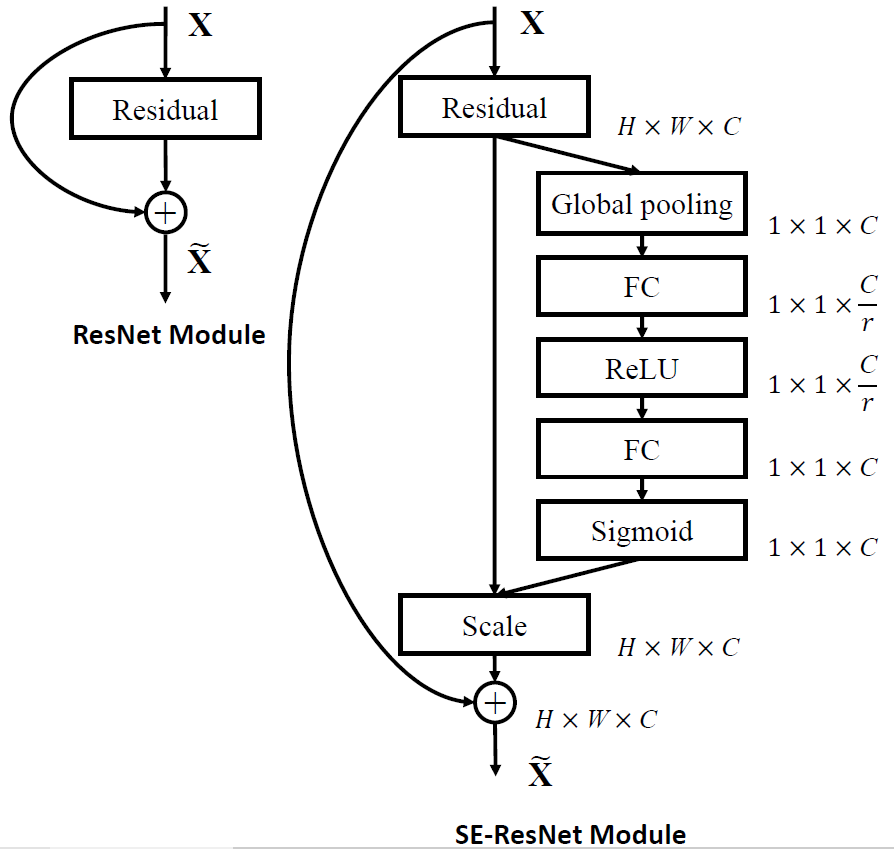
而在SE-ResNet中,Residual模块作为$\boldsymbol{F_{tr}}$,且Squeeze、Excitation和Scale操作在与恒等映射分支相加之前完成。作者也尝试将SE block加入在恒等映射与残差相加之后,但是实验表明在主干上存在的$[0,1]$Scale操作会使得较深的网络在输入层附近出现梯度消失的情况,导致模型难以优化。
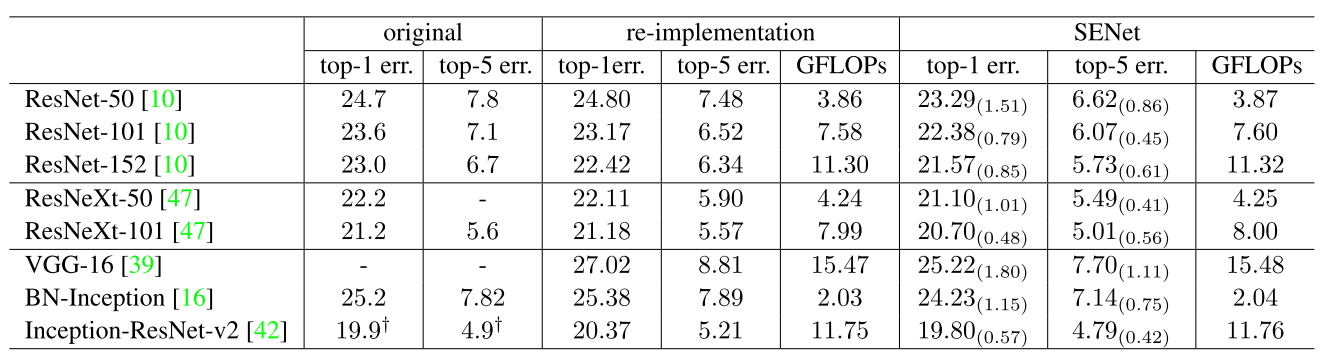 实验结果表明SENet能够在仅增加极少参数量与计算量的情况下,为网络带来比较显著的性能提升。
实验结果表明SENet能够在仅增加极少参数量与计算量的情况下,为网络带来比较显著的性能提升。
4. 分析
论文还对Scale输出权重的分布信息进行了分析,作者在ImageNet数据集中选取了goldfish、pug,plane和cliff 4个类别各50张图像对训练好的SE-ResNet-50进行测试,统计了网络5个深度处的权重分布,如下图所示。
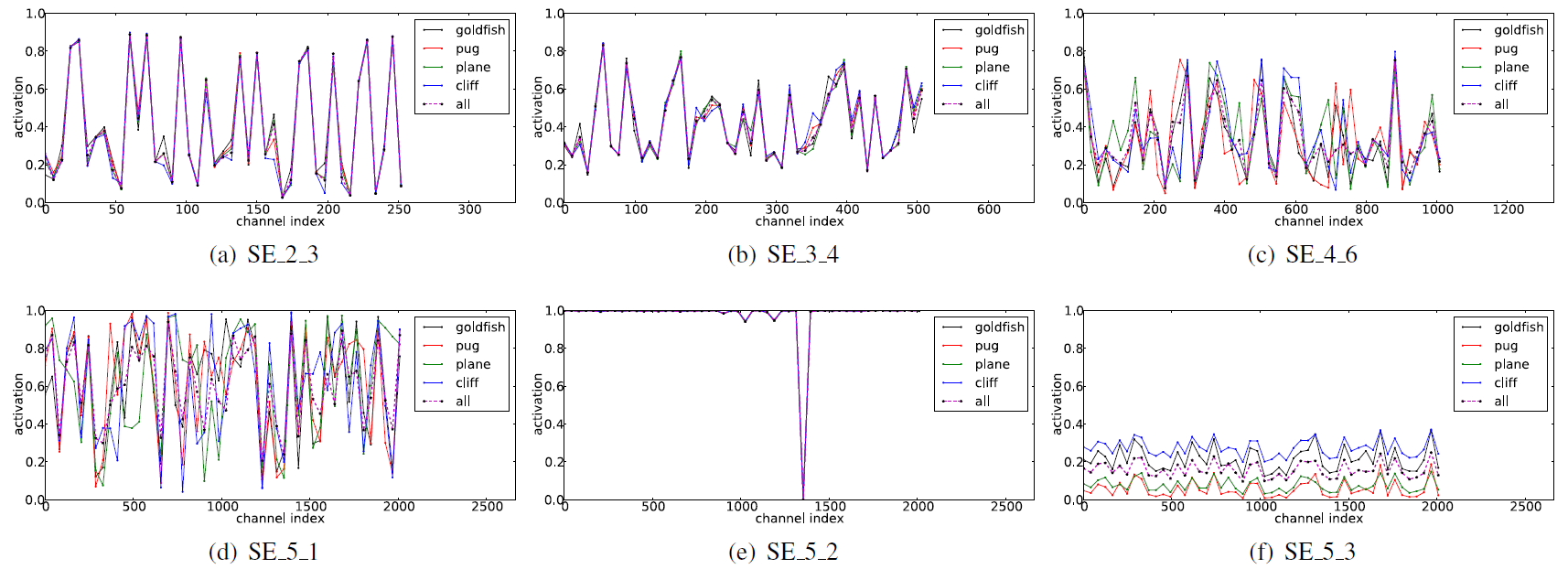 作者从图中总结出三个结论:
作者从图中总结出三个结论:
- 网络浅层(SE_2_3,SE_3_4),SE block针对不同类别输出的权重的分布高度相似,权重分布与输入的类别关系不大。这说明了卷积神经网络浅层提取的特征较为低级,主要为轮廓、边缘、纹理、斑点、颜色等具有共性的特征,能够被不同的类别所共享。
- 网络中层(SE_4_6,SE_5_1),不同类别的曲线开始出现了明显的差别,权重分布与输入类别有较大的关联,SE block在网络中层能够发挥较大的作用。
- 网络深层(SE_5_2,SE_5_3), SE_5_2和SE_5_3(SE-ResNet-50的最后一个卷积层)中不同类别权重分布几乎相同,尽管SE_5_3中不同该类别权重的激活幅度有所差异,但是这种差异能够被后续的全连接分类器有效调整。这说明了网络深层的SE block的重要程度不及浅层,将其去除能够进一步减少网络的参数量,而网络的性能只有轻微的损失。深层响应模式相同的原因也许正说明了SENet的特色所在——仅关注通道维度的信息,然而高级特征的差异性更可能是在空间维度体现的,而非通道维度,因此SENet无法通过通道维察觉到高级特征的分布情况。
References
[1] https://towardsdatascience.com/review-senet-squeeze-and-excitation-network-winner-of-ilsvrc-2017-image-classification-a887b98b2883
[2] https://cloud.tencent.com/developer/article/1119233
[3] https://zhuanlan.zhihu.com/p/32702350
[4] https://blog.csdn.net/u011501388/article/details/80389164